
Hola, en este articulo te presentaremos a Amazon Web Services, que es el lider mundial en servicios web en la nube, superando a Google y a Microsoft.
Comenzaremos el artículo con algunas definiciones que te ayudarán a contextualizar y entender lo que es Amazon Web Services.
Amazon Web Services, también conocida como AWS, proporciona una plataforma de infraestructura escalable. En otras palabras, proporciona infraestructura de Tecnología de la Información (TI) para empresas en forma de servicio web (cloud computing). Gracias a esto las empresas como Netflix, la NASA, Expedia, Pinterest o la CIA ya no tienen que gastar grandes cantidades de dinero en servidores e infraestructuras de TI ya que AWS garantiza una plataforma segura y confiable.
Amazon Web Services ofrece herramientas en las siguientes categorías:
● Cloud computing
● Bases de datos
● Creación de redes virtuales
● Aplicaciones empresariales
● Almacenamiento y gestores de contenido
● Inteligencia de negocios o Business Intelligence (BI)
● Machine Learning
● Gestión de aplicaciones móviles
● Internet de las cosas (Internet of Things)
● Herramientas para desarrolladores
● Media Services
● Seguridad y control de acceso
● Servidores de videojuegos
● Herramienta para desarrollo de videojuegos
A continuación, te contamos un poco sobre las herramientas que hemos usado:
DynamoDB
¿Has jugado Clash of Clans? ¿The Simpsons Tapout? entonces indirectamente usaste DynamoDB que es un servidor de bases de datos no relacionales, puede ser usado de forma paralela con servidores relacionales o de manera independiente.
Su contenido está expresado en JSON (un formato ampliamente conocido), y su principal característica es que, al ser no relacional, no tiene una estructura de datos estática, permitiendo así una mayor versatilidad en bases de datos relacionales. Se debe definir las relaciones y las columnas que la base de datos va a tener, cada objeto almacenado es independiente y no tiene una estructura definida.
Por ejemplo, en bases de datos relacionales, uno debe definir primero la estructura, sus tablas y relaciones, y cualquier cambio en los objetos que se almacenan, esta estructura estática debe actualizarse.
En bases de datos no relacionales, se puede enviar cualquier cantidad de información en un objeto, esta información es independiente, pero puede contener desde 1 propiedad (columna, atributo) hasta N siendo que cada objeto puede tener N-x propiedades.
fácilmente entendible con este ejemplo:
objeto: {id: 1, playerName: “player 1”, score: “123”}
objeto: {id: 2, playerName: “player 1”, ipAddress: “127.0.0.1”, DOB: “1980-01-01”}
Ambos objetos existen dentro el mismo contexto, pero su contenido es distinto, pueden imaginar el uso en aplicaciones de análisis de datos, aplicaciones médicas, información gubernamental, inventarios, ranking o estados de personajes en videojuegos, etc.
Su uso puede ser combinado con Bases de datos relacionales, porque como habrán notado, los objetos almacenados en DynamoDB carecen de relación con otros objetos, el cual guarda toda la información plana dentro el objeto, y se puede usar una BD relacional para mantener consistencia.
Ejemplos de Aplicaciones sin servidor utilizando DynamoDB:
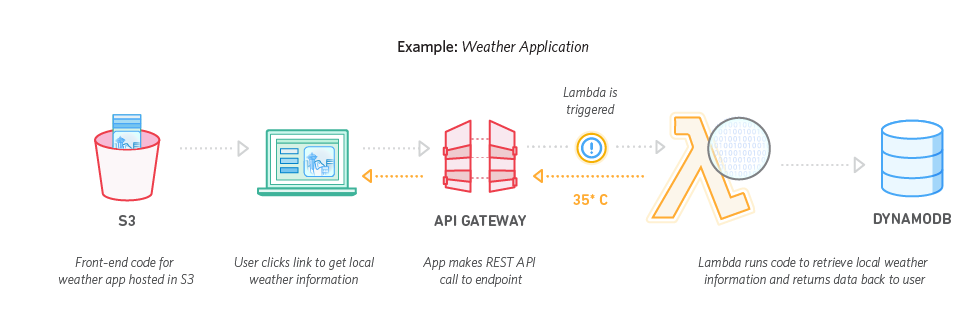
Fuente: aws.amazon.com
Para más información ingresa al siguiente link: https://aws.amazon.com/es/dynamodb/
Aplicaciones de chat para móviles:
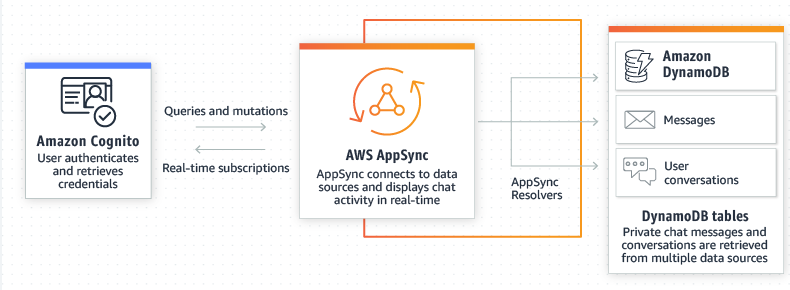
Fuente: aws.amazon.com
Para más información ingresa al siguiente link: https://aws.amazon.com/es/dynamodb/
Transmisión de datos para medios sociales (redes sociales):
Fuente: aws.amazon.com
Para más información ingresa al siguiente link: https://aws.amazon.com/es/dynamodb/
Otros servicios en AWS
Kinesis Stream
¿Qué ideas se te ocurren cuando necesitas un flujo constante de información volátil? si no te sirve esta información, ¿para qué usarla?
Bueno, AWS Kinesis stream tiene esa característica, imagina que es como una tubería (pipeline) por donde fluye información, desordenada, cruda. Esta información viene ordenada en “shards” por una única llave de partición.
Imagina un disco duro tradicional, la información era guardada en clusters o en sectores, en el caso de Kinesis la información es guardada en shards. Cada shard contiene una o varias entidades (objetos) fluyendo dentro el stream, asociados por una llave de partición que usualmente puede ser el identificador del objeto.
Esta información tiene un tiempo de vida limitado, por defecto desaparece en 24 horas o cuando haya sido correctamente consumida. Esta información en algún momento debe ser utilizada, para eso tenemos funciones Lambda (hablaremos de ello en breve), que generan eventos que muchas veces son aplicaciones que deben hacer algo con esa información.
Veamos un par de ejemplos reales para ilustrar mejor el uso de Kinesis.
Fotografías en una red social:
Si tomas una foto y la subes a una red social, por temas de performance, esa foto debe tener varias presentaciones, en tamaño pequeño para tu portada o para tu lista de fotos, en tamaño mediano para dispositivos móviles y tamaño real para verla completa. La foto que subiste debe ser de tamaño considerable (en términos de espacio que ocupa) por tanto cualquier red social no quiere cargar estas fotos en tu lista de fotos por ejemplo ya que tardaría, consume mucho ancho de banda y perderían usuarios. Lo ideal es tener estas versiones de fotos ya almacenadas desde el momento en que subiste tu foto.
Imagina esto, subes la foto, esta foto se manda a Kinesis y fluye hasta que una función Lambda la atrapa, esta función Lambda llamará a algún código hecho por alguien que tomará la foto, le hará un resize para las distintas presentaciones que necesita la red social y llamará a un servicio, una base de datos, un folder remoto, etc, para guardarlas. Así la siguiente vez que veas tu red social y subas una foto, esta se encontrará en varias presentaciones que cargarán inmediatamente porque desde que subiste la foto, ellas ya fueron creadas (todo eso ocurre de manera asíncrona pero bastante rápido).
¿O que tal si necesitas hacer análisis de datos? por ejemplo, tienes una aplicación médica donde tienes un sistema remoto que guarda datos de pacientes y quieres hacer un análisis de datos que tome en cuenta las edades de los pacientes, problemas comunes de salud, ubicación de los pacientes respecto a sus problemas, prescripciones médicas, cantidad de visitas y otra información muy valiosa para análisis estadístico. Lo que haces es tener algún agente que constantemente lea la base de datos del sistema remoto y empuje nuevas transacciones (cambios de datos) a Kinesis, luego tu función Lambda dispara otra aplicación que discierne las entidades pasando por Kinesis, encuentra pacientes y los manda a un data-lake, API, Database, etc. Para
que luego puedas hacer tus reportes, análisis, etc. (¿escuchaste el término analytics? pues ahí tienes).
Hay muchas posibilidades para Kinesis y es una forma de mover datos que apenas está comenzando.
Lambda Functions (Aplicaciones sin servidor)
Estas funciones son más bien como triggers o detonantes que son activados cuando algunos eventos ocurren en el universo AWS, estos eventos pueden ser Amazon S3 bucket (contenedor de archivos), una tabla en Amazon DynamoDB, Kinesis stream o notificaciones SNS (sistema de mensajería que notifica a varias aplicaciones en paralelo).
¿Sus usos? pues muchos y ¡muy variados! vamos a pensar en el ejemplo de las redes sociales usando Kinesis. Subes una foto a tu red social, esa foto pasa a través de Kinesis, pero el eslabón perdido en ese flujo de trabajo es Lambda, cuando un evento ocurre en Kinesis, se dispara 1 o varias funciones Lambda, cada una con una única responsabilidad que es llamar a alguna aplicación desarrollada previamente, por ejemplo, una image resizer. Estos eventos son variados dependiendo del servicio AWS que los genera, en el caso de Kinesis un PUSH de información, en el caso de DynamoDB cuando una tabla fue actualizada o una nueva entidad editada/insertada, o en SNS que se haya generado un mensaje, imagina que estás en un juego online y algún amigo ha ingresado al juego, eso es un evento que puede llamar a una o varias funciones Lambda que a su vez llaman a una o varias aplicaciones que hacen distintas cosas como notificarte que John Doe ha iniciado sesión, o que NoobMaster69 ha matado a alguien o que Brittany ha subido una nueva foto en su perfil.
Las funciones Lambda están siempre “escuchando” por estos eventos y se las debe configurar para que se disparen con uno u otro de ellos, y también configurarlas para llamar a la aplicación que deben.
Si la aplicación por algún motivo falla, devolverá una excepción a Lambda y Lambda entenderá eso como “el destino de esta información ha fallado, volveré a mandar lo mismo hasta que todo salga bien, o que la información expire” entonces si algo fatal ocurre (servicios caídos, base de datos inexistente, entidad no encontrada, etc) lo más importante es no perder la información, entonces Lambda la vuelve a mandar hasta recibir un resultado positivo de la aplicación O que expire la información (ejemplo: Kinesis stream mantiene los datos por defecto 24 horas).
Kinesis AWS UI:
Ejemplo de Aplicaciones corporativas en AWS
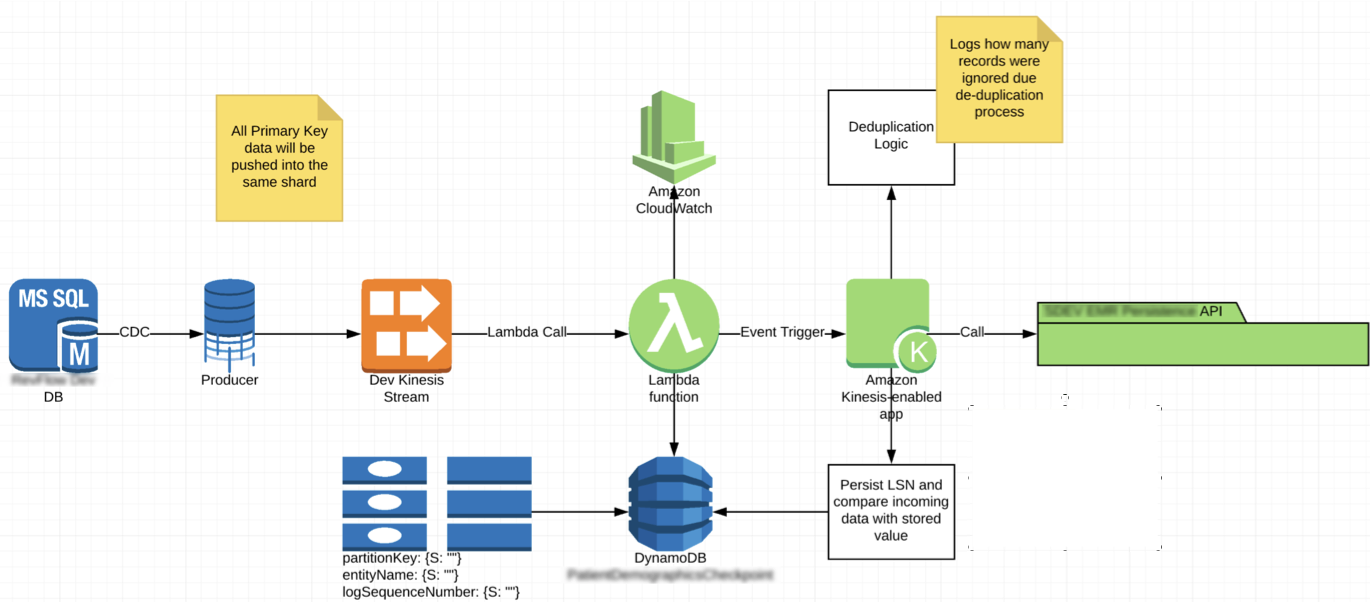
Fuente: AssureSoft.
Resumiendo, el flujo: Los Agentes que viven en un servidor de Base de datos Microsoft SQL (producers) constantemente obtienen información directamente de la BD, esta información la mandan a Kinesis, quien a su vez la hace fluir, de esta forma una función Lambda atenta a esto llama a una aplicación externa quien a su vez llama a un API, ¿resultado? ¡una integración entre 2 aplicaciones completamente distintas sin haber tocado código en ninguna de las dos. ¡No es esto realmente increíble!
Precios de los servicios en AWS
Así es, todo esto cuesta, y este es un apartado importante ya que hay muchas empresas que empiezan de manera muy agresiva y optimista, contratan servicios y planes que son demasiado abundantes para su uso y terminan en problemas financieros, en resumen, si te emocionas con AWS sin hacer un estudio de tus servicios, tu tráfico de datos, usuarios, clientes vs los planes de AWS, entonces puede ser complicado.
Siempre es buena idea analizar, primero si realmente necesitas usar AWS (un hola mundo o una tienda pequeña quizás no necesiten AWS pagado) y segundo tener una idea del tráfico que tendrá tu sistema.
Los costos son elevados, pero a la larga ahorras mucho tiempo y trabajo. Además, claro que AWS tiene su capa gratuita para que pruebes sus servicios (es más, puedes crear cuentas gratuitas y tener estos servicios gratis con límites claro), sugiero entres a este agradable mundo con ideas claras de lo que quieres entender o lograr. Mediante la capa gratuita podemos probar muchos de los servicios AWS incluso para ambientes de producción durante un año sin costo alguno.
Saludos y buena suerte, terrícola.







